
When Anyone Can Build, Who Decides What Ships?
When anyone can build software, the barrier to creation collapses faster than our ability to understand what we build. As AI accelerates development, verification falls behind. Responsibility no longer distributes across teams. It concentrates in the hands of the person who presses deploy.
There is a familiar character in the history of software. The marketing or product visionary with a “brilliant idea to change the world as we know it.” They understood the problem, the user, and the opportunity. Often more clearly than anyone else in the room. For decades, this person existed at the edge of execution. They could imagine the product, describe it, pitch it, and advocate for it.
But they could not build it.
Between idea and reality stood a system of friction: engineers, requirements, specifications, architecture, testing, review cycles, approvals, and release gates.
This system did not only involve engineers. Designers, usability specialists, and product thinkers translated ideas into interfaces, flows, and human experience. They shaped how software was understood and used. They, too, were part of the friction process.
That friction was not inefficiency. It was filtration.
An idea did not become software because someone imagined and believed in it. It became software because it survived experts translation into something that worked, scaled, and did not break the system it entered.
This process was slow, often frustrating, and sometimes bureaucratic. But it enforced a simple constraint: the people responsible for deployment were, in some meaningful way, connected to understanding what was being deployed.
That constraint is dissolving.
Today, that same person can open a laptop, write a structured instruction, and invoke a system of models and agents that generates:
• interfaces
• backend logics
• integrations
• deployment scripts
In hours, not months—compressing what once required coordinated work across design, product, and engineering teams into a single, accelerated workflow.
The distance between idea and implementation has collapsed.
This is real.
It is not perfect. Infrastructure still breaks. Integrations still fail. Edge cases still exist. Reality remains messy. But the direction is clear.
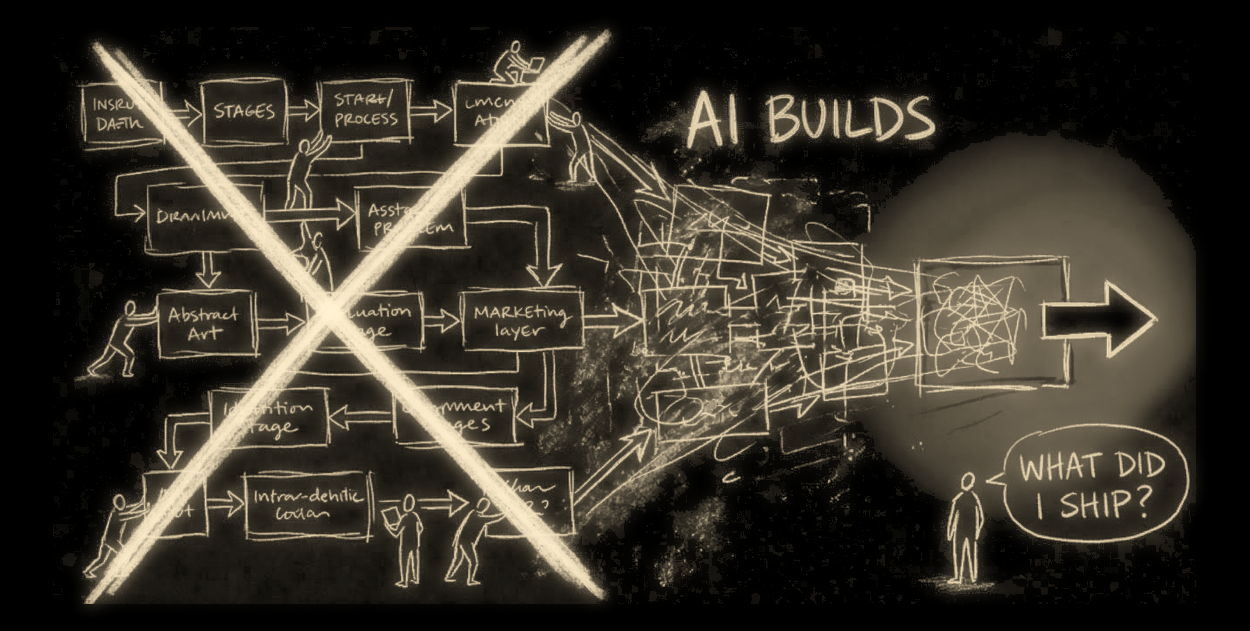
The barrier to creating software is collapsing faster than the ability to verify it.
This is the shift that matters.
Not that software is, and in any was, 'easier to build'.
But that it is 'easier to deploy than it is to understand'.
Historically, building and understanding were tightly coupled. From a code perspective:
• Engineers wrote the code.
• Other Engineers reviewed the code.
• Again Other Engineers deployed and maintained the code.
Responsibility was distributed, but responsibility it 'was also informed'.
The system assumed a basic alignment:
the person deciding to ship something had a reasonable grasp of what that thing was—because it had been challenged and shaped by experts at every step.
That assumption is no longer safe.
We are entering a phase where:
• systems are generated, not written
• outputs are assembled, not deeply understood
• functionality is observed, not fully reasoned through
This creates a structural condition:
Capability without Comprehension.
And this condition introduces a new form of risk.
Staying with code, the risk is not that bad code exists. Bad code has always existed. The risk is that decisions are made about code that is not fully understood by the person making them.
A system does not care whether the code was written by a senior engineer or generated by a model, or how quickly it was produced, or how elegant it appears.
It only cares about outcomes, like:
• Does it fail?
• Does it expose data?
• Does it behave unpredictably?
And when those failures occur, responsibility does not disappear.
It concentrates.
Someone still presses “deploy.” Someone still allows the system to act, even if they did not write the code, even if they do not fully understand it. This is the inversion.
As code becomes cheap, responsibility becomes expensive, not because the stakes have changed, but because the relationship between capability and understanding has broken.
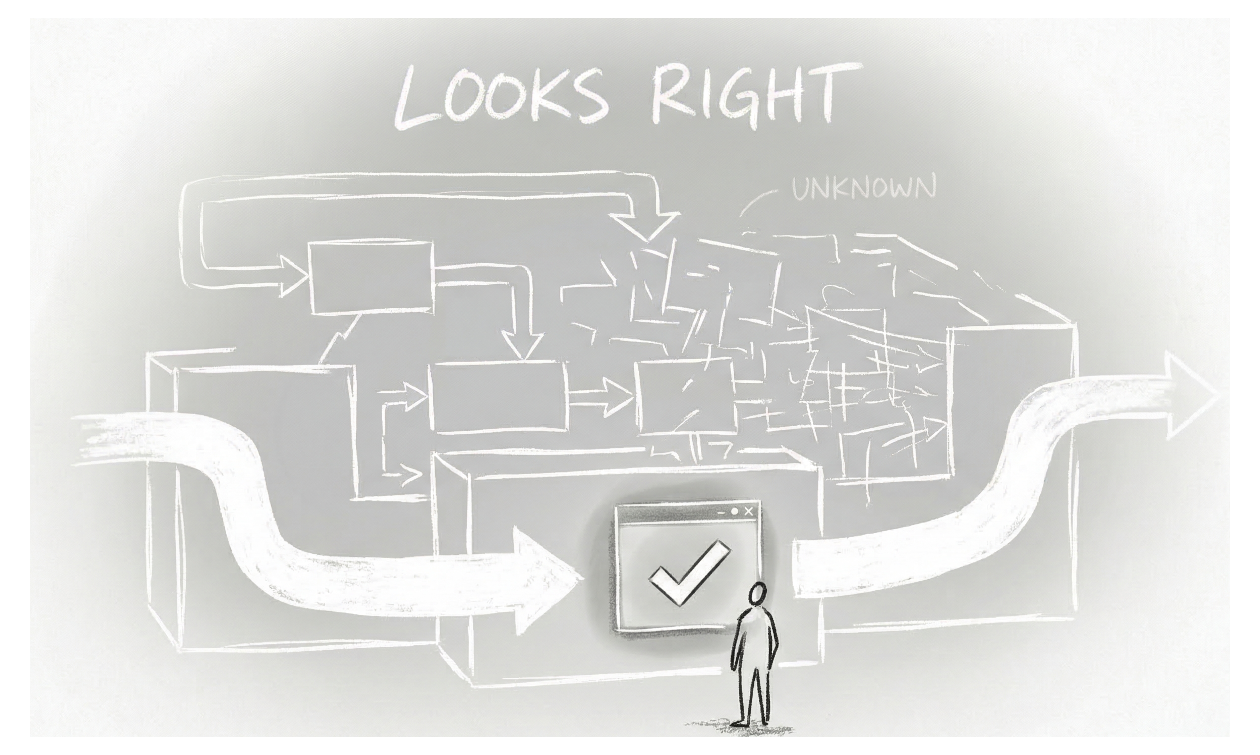
The industry has not yet adjusted to this. We still operate with assumptions formed in a different era: that review implies understanding, that testing & QA implies coverage, that deployment implies confidence.
But in a world of AI-assisted generation, those assumptions begin to weaken. You can observe that something works without knowing why it works. You can test common paths without seeing rare failures. You can deploy quickly without fully mapping the system you are releasing. This creates a gap.
• Not a tooling gap.
• Not a productivity gap.
A decision gap.
When anyone can build, the system is forced to confront a new question.
• Not whether something runs.
• Not whether it compiles.
• Not whether it appears correct.
But whether it should be deployed at all. Whether it is safe enough, reliable enough, and understood enough to act on.
This is not a question generation systems can answer. They produce outputs, not judgments. It is not a question intuition can resolve, especially as systems grow in complexity beyond what any single person can fully grasp.
And it is not a question that can be scaled through manual review, because the volume of what is created now exceeds the capacity of what can be carefully inspected.
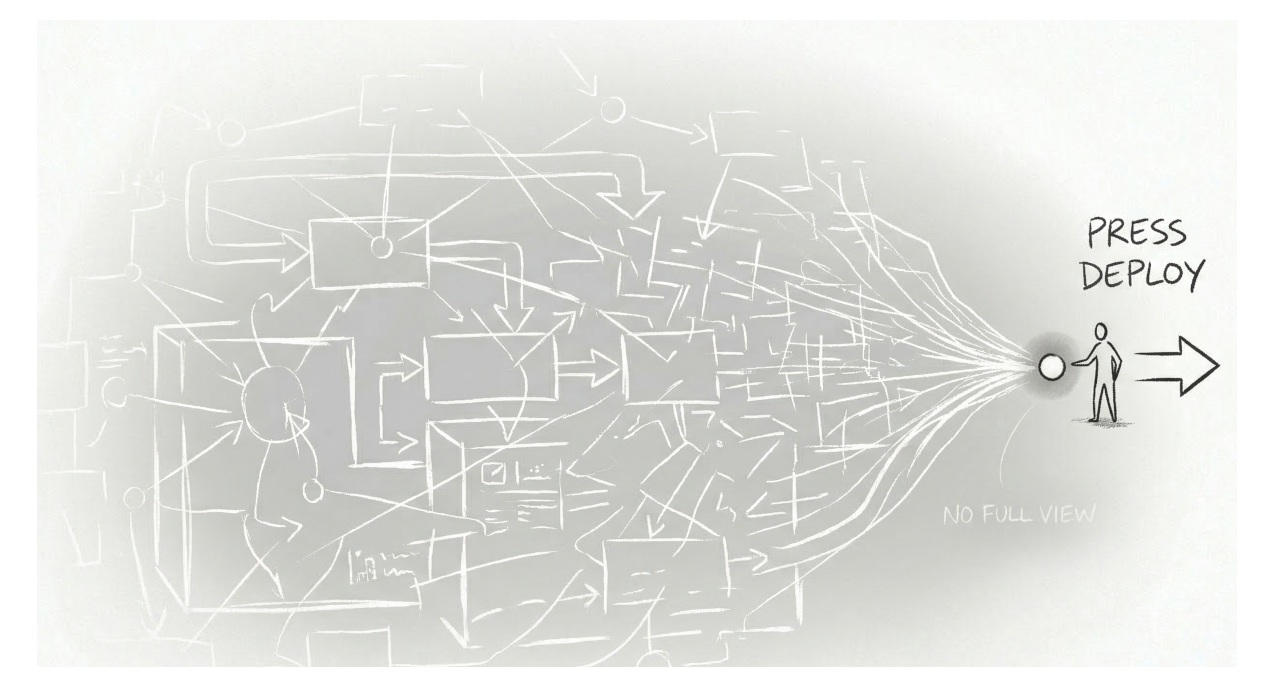
What emerges, then, is not a tooling problem, but a structural gap. A gap between what can be built and what can be responsibly put into the world.
And within that gap, responsibility does not disappear. It concentrates. The system does not absorb it, and the tools do not carry it. It remains with the person who decides to act, to merge, to deploy, to release. The same person who, until recently, stood at the edge of execution can now stand at its center, able to initiate systems that reach thousands or even millions of users. Alone.
But that shift in capability does not redistribute responsibility. It intensifies it, regardless of how that system was created or how well it is understood.
Closing that gap requires a new layer, one that does not generate or execute, but evaluates. One that takes the output of these systems and turns it into something that can be assessed, interpreted, and ultimately relied upon by the person who must decide what happens next. And who remains responsible and accountable for that decision.